sbt¶
Installation¶
Navigate to the project on which you want to use Hydra and add the following inside the file project/plugins.sbt (if the file isn't there, create it).
For sbt 1.3+¶
resolvers += Resolver.url("Triplequote Plugins Releases", url("https://repo.triplequote.com/artifactory/sbt-plugins-release/"))(Resolver.ivyStylePatterns) addSbtPlugin("com.triplequote" % "sbt-hydra" % "2.3.11")
For sbt 0.13.13 to 1.3.13¶
resolvers += Resolver.url("Triplequote Plugins Releases", url("https://repo.triplequote.com/artifactory/sbt-plugins-release/"))(Resolver.ivyStylePatterns) addSbtPlugin("com.triplequote" % "sbt-hydra-legacy" % "2.3.11")
Starting with the Hydra 2.3.0 release a new sbt-hydra-legacy plugin has been introduced to support compilation with older versions of sbt (from 0.13.13 up to 1.3.13). Other than the supported sbt version, there are really no differences between the sbt-hydra and sbt-hydra-legacy plugins. In fact, all features and API offered by sbt-hydra are exactly the same in sbt-hydra-legacy.
Upgrade strategy¶
As sbt-hydra and sbt-hydra-legacy both work with sbt 1.3, the recommended strategy to avoid a big bang upgrade is to first upgrade your project to sbt 1.3.13 (while using sbt-hydra-legacy), and then switch to use sbt-hydra as the latter is compatible with sbt 1.3+. At this point, you may move forward with upgrading the sbt version to 1.4 and later.
sbt fails to resolve the Hydra artifacts¶
Warning
If sbt fails to resolve the Hydra artifacts please read this section for how to troubleshoot the problem.
License activation¶
If you're using Hydra on your developer machine, you need to activate a Hydra license before you can compile with Hydra. See the License section for how to do this on other build tools. Inside sbt, type the following, using the actual license number you obtained:
> hydraActivateLicense XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX-XXXXX [info] Activating using https://activation.triplequote.com/algas/. This may take some time.. [info] License successfully activated A `reload` is required to compile with Hydra. Do you want to reload now? [Y/n]
Note that right after activating the license, it is necessary to reload the build or Hydra will not be used.
Compiling with Hydra¶
Now that Hydra is installed, let's check how it works. Enter the sbt shell and execute the compile task:
$ sbt [info] ... > compile [info] Compiling 80 Scala sources to ... [info] Using 4 Hydra workers to compile Scala sources. [info] Starting MetricsService in /home/john/.triplequote/metrics [success] ... >
When executing the compile task you should notice the message [info] Using 4 Hydra workers to compile Scala sources. (the number of workers may differ, as it depends on how many physical cores your machine has and how many Scala sources need to be compiled).
Congratulations, you have successfully installed Hydra!
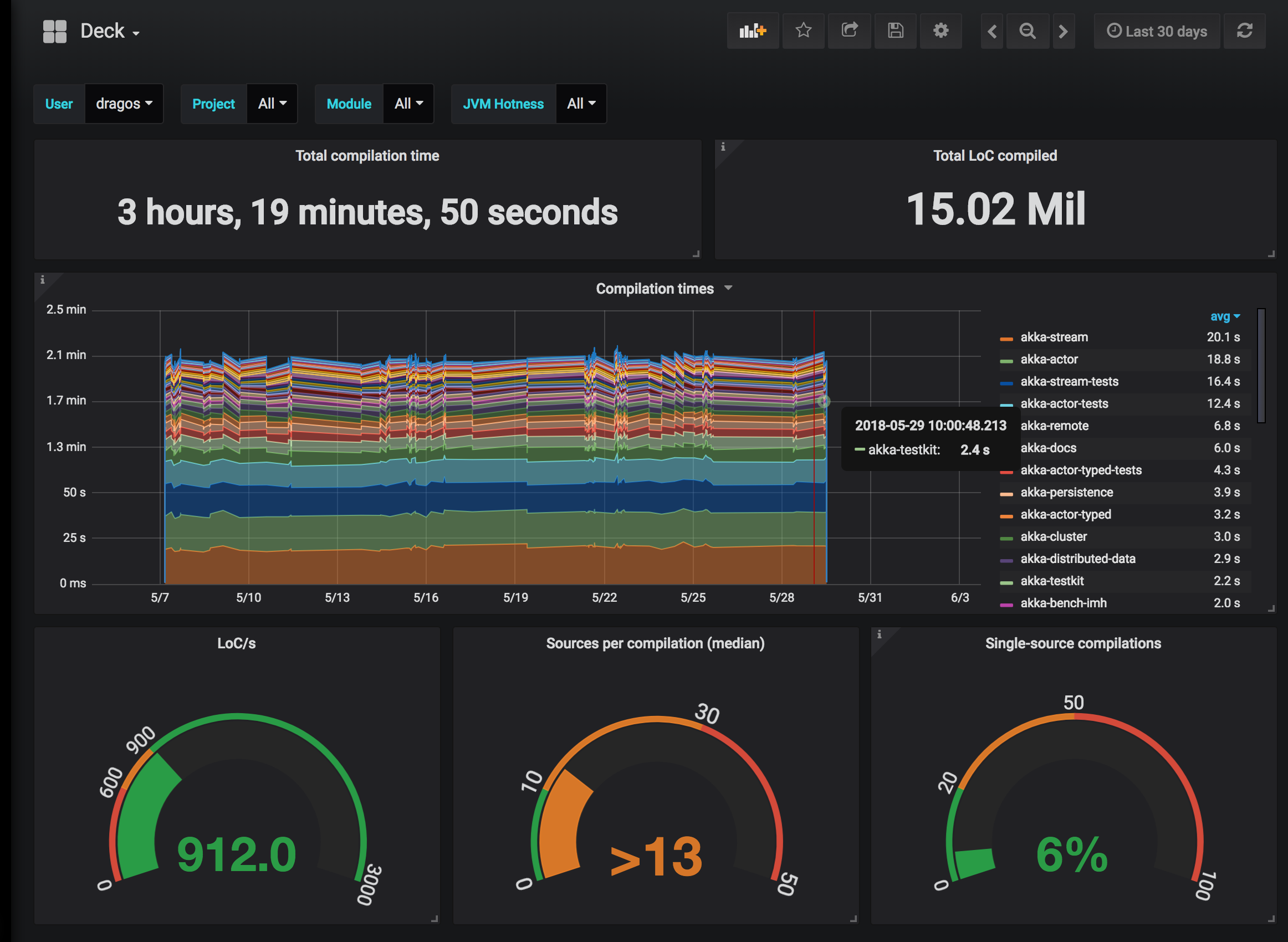
Compile-time monitoring!¶
While compiling your Scala source files, Hydra also collects compilation metrics that help you keep compile time under control. With the help of a modern web-based dashboard, you can track how compilation time evolves on your project, commit after commit. Even more importantly, you can prevent unexpected compile time deteriorations to land in the development branch before hampering everyone's productivity.
In the sbt output above you might have noticed the message
[info] Starting MetricsService in /home/john/.triplequote/metrics
This informs you that Hydra will try to push compilation metrics to a service that is expected to run on localhost (note that Hydra will work just fine also if you decide not to install the dashboard).
If you have Docker installed, the dashboard may already be up and running. To set-up the dashboard in other scenarios, please read the installation instruction.
Know your memory requirements¶
Hydra has slightly higher memory requirements than regular Scala, so make sure you keep an eye on the JVM behavior. If compiling your codebase using Hydra doesn't deliver the desired speed up, try to launch sbt with more memory:
$ sbt -mem 4096 [info] ...
Note
If your project has a .jvmopts file then the value passed to -mem is ignored. In this case, simply increment the heap value (-Xmx) declared in the .jvmopts file.
Also, see tuning memory for how to make the sbt memory configuration part of your project.
Benchmark!¶
Benchmarking how Hydra performs on your project couldn't be easier. Simply enter the sbt shell and execute the hydraBenchmark command:
$ sbt [info] ... > hydraBenchmark 10 ... // Hold on, benchmark is running!
The hydraBenchmark command will compare the performance of Hydra versus vanilla Scala for all projects in your build, producing a detailed report with the speedup delivered by Hydra. Read Benchmark for the glorious details on how the hydraBenchmark command works.